........ I have been playing with Midjourney for a few weeks. They use a Discord bot as their user interface, which can be a bit harder for new users, but I guess it was faster to develop in that way.
As a design exercise, I want to try building a similar Discord bot, deployed to Google Cloud. My bot will generate
mandalas using the
RandomMandala Python library.
My goal is to build a bot that can scale horizontally indefinitely and automatically, without requiring updates to the code when scaling up or down or manual interactions.
I have not had the opportunity to use Google Cloud for a production project yet, but rather pet projects, so this will be a good opportunity for me to learn. I will experiment with different approaches, starting with the simpler ones.
Simple bot using the Discord Gateway, single app
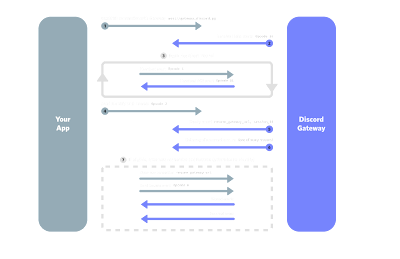
That's the easiest approach to write a bot. You use
discord.py Python library, write a small standalone application which listens to bot commands and replies accordingly. The Discord server and you bot uses a combination of HTTP API and websockets to communicate.
To develop a Discord bot, you will need to create a bot account on the
discord.com/developers website. This process is well documented
here, I'll not address it in this post, but rather focus on the cloud modules.
Relevant Python code below (the full code is here):
[...]
@client.event
async def on_message(message):
if message.author == client.user:
return
if message.content.startswith('$hello'):
await message.channel.send('Hello!')
client.run('your token here')
It simply reads all messages in the Discord guild, and if a message starts with "hello", it replies with "Hello". You execute it a a console application. Simple.
There's one major issue with this approach: it does not scale horizontally. There can be just one process, so the only way to scale when more users joins your bot is to allocate more CPU and memory to the machine. Not ideal.
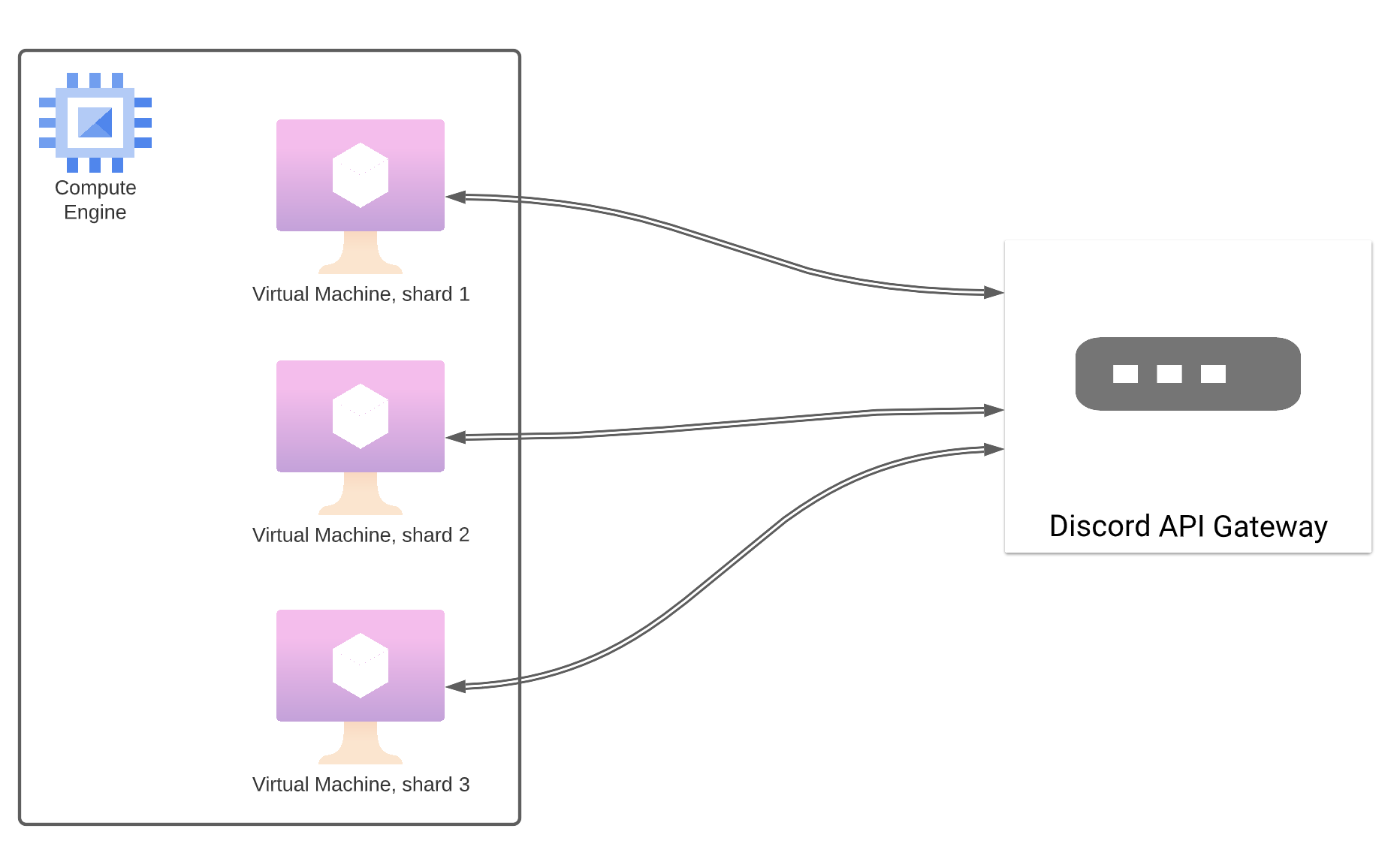
Simple bot using the Discord Gateway, with sharding
Sharding is a technique that allows the bot code to start more
instances, each instance handling several Discord guilds. The easiest way to implement this is to use the
AutoShardedClient class which does everything for you under the hood. When the bot starts, it computes the optimal number of shards based on how many guilds your bot is serving and then automatically starts those
instances.I've used italic for instances because it's not yet clear to me what are these. Are these threads ? Does it spawn multiple processes ? Probably threads. This approach is not really what I want (read below why), so I'll not dig into understanding how it works internally.
The issue with the AutoShardedClient is that the code still runs on the same server. Yes, it's probably better in terms of handling multiple users, but it still shares the same CPU and memory. Not what I want.
There's another approach, which is a bit more complicated, where you control the shard associated to each bot instance and the total number of shards. I found a NodeJS implementation,
here. I did not spent too much time with this, as I suppose you need to know the number of shards in advance. Should you want to deploy more shards, you need to stop the bot, update the shard count, then restart again. Not nice.
I'm not going to try this.
However, just for clarity sake, let's draw a deployment diagram in GCP to illustrate how our bot would be deployed. I've chosen to run a few virtual machines on top of Google Compute Engine as our bot is essentially just a console application.
Alternatively, you could deploy the bot using the Google Kubernetes Engine, which is a more robust approach but also more complex. However, it may not be easy to set up automatic horizontal scaling using this method, so I will not delve into it further.
Discord bot using Interactions and Webhooks
In the previous sections, I presented one approach to writing Discord bots and discussed why it is not suitable for horizontal scalability.
There is, however, another way to build a highly scalable bot that uses
Interactions and Webhooks instead of connecting to the Discord API Gateway via websockets.
The communication protocol is more transparent and easy to understand using this approach. Whenever a
slash command is invoked in your Discord guild, the Discord server invokes the bot via an HTTP POST request to a URL configured as the entry point for the bot application. The bot can then respond to the Discord user interaction using simple HTTP POST/PATCH/DELETE requests. This makes the bot behave like a regular web application rather than using the websockets protocol. Nothing fancy, but everything is transparent and easy to manage, as we're now talking of a regular web application instead of a websockets protocol. And that's amazing, because now I have so many options to scale our bot (which is just a web application now) within GCP.
There are several options for deploying this bot in GCP, ranging from simple to complex.
Deploy using a single Cloud Function
Although it is a simple solution, this approach will still work and be horizontally scalable. You can deploy all the code in a
single serverless function that listens for incoming traffic. When it receives a command, it generates a mandala using the
RandomMandala lib, stores the image in a
Google Bucket, and then sends an HTTP POST request to the Discord server to provide the image to the human user.
Although this architecture works and is horizontally scalable, with GCP spawning new instances as needed, it is not optimal. If image generation requires a certain amount of RAM or CPU, we must set limits on the single cloud function we have. However, we cannot impose a limit on the number of parallel instances of this function because we want the bot to scale indefinitely. To avoid wasting resources, we should consider splitting the work of the single function into two separate functions: one that handles incoming HTTP requests and another that generates images and sends them back to the user.
Deploy using two Cloud Functions and a PUB/SUB topic
Here we are using two serverless functions. One to process the incoming HTTP POST from the Discord server (when the user invokes a slash command) and another function to generates the mandala image and post it back to the Discord server via webhooks. The same storage bucket is used.
This approach is already way better than before:
- we can use limit the resources for the cloud function which received the incoming data. There is no need for a lot of CPU or memory to receive a few hundred bytes JSON message and post it to a PUB/SUB topic. Because of using very thin machines, we can still afford to let the number of parallel instances to grow as much as needed.
- we can limit the number of parallel instances for the function which generates the mandala to a lower number. As far as the Discord user receives a reply immediately saying "your request is being processed, should take less than 3 minutes", the user is happy (we can estimate the time until the user is served based on the current system load)
Deploy using three Cloud Functions and two PUB/SUB topics
For the same reasons as above, we might want to split the second function (the one that generates the mandala and sends the user the reply back) once more. Keep one function which only generates images and create another function to send the reply back to the user.
By splitting the functions in this way, we can use powerful machines specifically for generating mandala images and thinner machines for sending data back to the Discord server/user via webhooks.
Deploy using Cloud Tasks
Using serverless functions and PUB/SUB topics is convenient and effective. It's not the single possible approach. Cloud Tasks is essentially a pub/sub topic on steroids, with additional features that automatically repost a message when processing fails, allow you to control the rate at which messages are delivered to limit the load on your consumers, and implement task deduplication so that even if a message is posted twice, it will only be processed once.
Here is a comparison between PUBSUB and Cloud tasks.
With Cloud Tasks, workers can run in App Engine as web applications, or you can use your own workers deployed in any environment you choose. Cloud Tasks invokes the worker via plain HTTP requests and the worker returns HTTP status codes to notify whether the processing was successful or not. We can still use
serverless functions as workers, if we want. This is cost efficient for low loads, as the cloud function instances scales down to zero when nobody is using the bot. We can also use
Cloud Run if we want to deploy our works a Docker containers. Still cost effective, it can scale down to zero when no usage. Or we even use a
Kubernetes deployment.
Next, I'm going to write a post for each of the approaches presented above.






Comments
Post a Comment